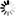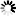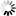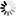|
|
|
|
Article ID: 2931
Last updated: 05 May, 2020
Additional information:
Problem: Test scenario and troubleshooting of Open-E DSS V7 (up60) cluster shutdown and start-up. It includes a step-by-step description of the cluster shutdown and start-up and troubleshooting in case of common start-up problems. Symptoms: Step 1. Ensure both Replication state fields of Resources pool are synced (in Setup -> Failover -> Failover Manager). Otherwise, wait until synchronization is completed. Move all resources to one node (from Node A to Node B) using the "move to remote node" button in the Setup -> Failover -> Resources Pool Manager. Step 2. Shutdown the node without resources (Node A) from the WebGUI: Maintenance -> Shutdown -> System Shutdown. Node B Failover status after shutdown of Node A.
Step 3. Shutdown Node B from the WebGUI: Maintenance -> Shutdown -> System Shutdown. Step 4. Power on Node B. Step 5. Start Failover on Node B in local start mode: Setup -> Failover -> Failover Manager -> Start button. Wait until Resources pool status will be active in the Failover Manager. Node B Failover status when running in local start mode
Step 6. Power on Node A. It should connect and join Failover automatically. Node A Failover status after joining the cluster.
Step 7. Move resources to the original state (from Node B to Node A) using on Node B: move to remote node button in the Setup -> Failover -> Resources Pool Manager. Solution: Case 1. In Step 6 after Node A join, when on both nodes, Cluster Status will show up as Running–Degraded and all Resources pool fields show active and synced.
Solution: 1. Continue with Step 7 (Move resources to their original configuration). 2. On console tools, start Maintenance Mode by selecting Ctrl+Alt+X->Cluster Maintenance Mode. 3. On GUI, Stop the cluster in Setup -> Failover -> Failover Manager. On the confirmation prompt, you must choose the stop and enable VIPs button.
4. Start the cluster again. Case 2. In Step 6 after Node A join, when on Node A Cluster Status will show up as Stopped (and on Node B as Running–Degraded) and in Resources pool, Replication state shows not synced (on at least one resource pool). Also, Event Viewer on Node A shows “Failed to join the cluster, incorrect configuration(errorcode:13).” error message. Node A (joining node):
Node B (active node):
Solution: 1. Please stop all running replication tasks on Node B (Configuration -> Volume manager -> Volume replication)
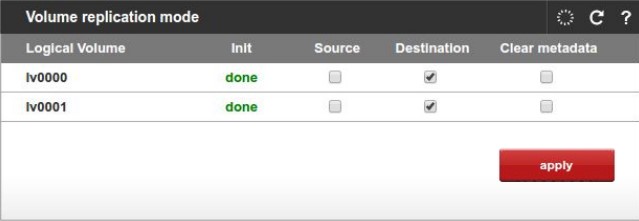
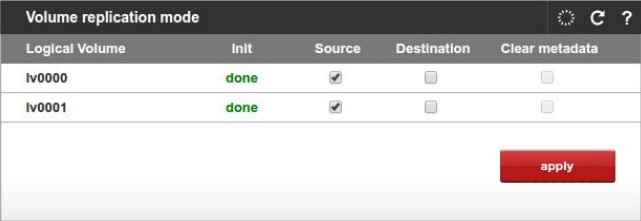
2. Ensure all volumes (which are used in the cluster) on Node A are marked as Destination (Configuration -> Volume manager -> Volume replication) and all volumes on Node B are marked as Source. If not, make appropriate changes. Node A (joining node):
Node B (active node):
3. Start all replication tasks on Node B (Configuration -> Volume manager -> Volume replication) 4. Ensure Replication state for both pools in Failover Manager (Setup -> Failover -> Failover Manager) on any node shows syncing in progress or synced. 5. Start cluster on Node A (joining node) in Failover Manager (Setup -> Failover -> Failover Manager) Possible cause of the problem: - during Node A joining (Step 6), connection errors on replication level or network issues occurred, - user has changed volume replication mode on node B while node A is off (after Step 2) - eg. change of one volume from Source to Destination and back to Source Case 3. In Volume replication mode (Configuration -> Volume manager), if Source / Destination checkboxes are "greyed out" and it is not possible to change the destination to source. (See the screenshot below.) The workaround is to click on task-start button and refresh the browser(F5).
General case. In some cases, your web browser may cache information from the GUI and show unexpected information. In such a situation you can refresh the browser using ctrl + F5 keys or refer to your web browser manual.
Share this article
Link to article
|
|||||||||||||||||||
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)